- Extreme Automation:
- Automated Conversion
- Automated Data Migration
- Strict Runtime Compatibility
Core Design Principles
The core principles of the FWD technology and methodology are extreme automation and strict compatibility. FWD is designed to ensure you can convert, build, run, and test your application without having to hand-edit the converted code. This cycle can be repeated many times, and newer drops of the application's ABL code base even can be substituted in over the course of a migration project, without adding significant effort to the overall project.
How is this possible? Support for each legacy feature is built into the conversion and runtime technology. If something is missing or broken, it is fixed in FWD once, rather than duplicating this effort across every application. To date, FWD has amassed a sizable feature set which already handles a wide range of application functionality. This includes GUI and CHUI support with Direct-to-WebTM deployment, application server, database access, and much more.
Automated Conversion
While the conversion itself is automated, manual preparation of a conversion project is necessary. This can take minutes to weeks, depending on the size and complexity of the application. This work includes:
- Collecting inputs.
- Creating conversion hints to allow FWD to make informed decisions.
- Devising strategies for any external dependencies (e.g., third party software, operating system or peripheral hardware dependences).
- Addressing syntax errors found by FWD in application code in early stages of conversion (in certain respects, the FWD code analysis is stricter than that of the ABL).
- Feature gap analysis.
Part of the early work in a conversion project is a gap analysis of the feature set used by the application compared to the feature set supported by FWD. If FWD is missing ABL features in use by the application, a plan must be made as to how to deal with these gaps. Either the features must be added to the FWD conversion and runtime code, or the features must be removed or replaced in the application code. While the gap analysis itself is an early project requirement, the implementation of any missing FWD features generally can be performed in parallel during the course of the project.
Once the up-front work is done, the automated conversion is run as a batch job. This can take seconds for a trivial test case of a few dozen lines, or hours for an application millions of lines in size. Early phases of the conversion read and analyze the schemata and source code, producing abstract syntax tree (AST) representations of these constructs. Thousands of conversion rules are then applied to these ASTs. This conversion logic analyzes, annotates, replicates, or otherwise transforms these ASTs in a pipelined process which eventually has gathered enough information to produce a Java replacement for the application.
The FWD conversion identifies ABL statements, built-in functions, methods, and attributes used by an application. It recognizes higher level constructs as well, such as transactions, resource scopes, and common code patterns. For each of these, an equivalent Java code pattern with one or more API calls to the FWD runtime environment is emitted into converted code.
Some amount of refactoring is done, to the degree possible without compromising the essence of the program's control flow. For example, temp-table and UI frame definitions are extracted from procedures and emitted into discrete Java interfaces and classes. Converted business logic references these resources. With input from developers, dead code can be identified and removed as part of the transformation of the application.
Inputs
The primary inputs to the automated conversion process are:
- exported Progress database schemata;
- Progress application source code;
- conversion hints;
- optionally, custom conversion logic and special-purpose Java application code;
- exported database data to be migrated to a new database.
Phases of Conversion
At a high level, the conversion process consists of four logical phases (see Figure 1):
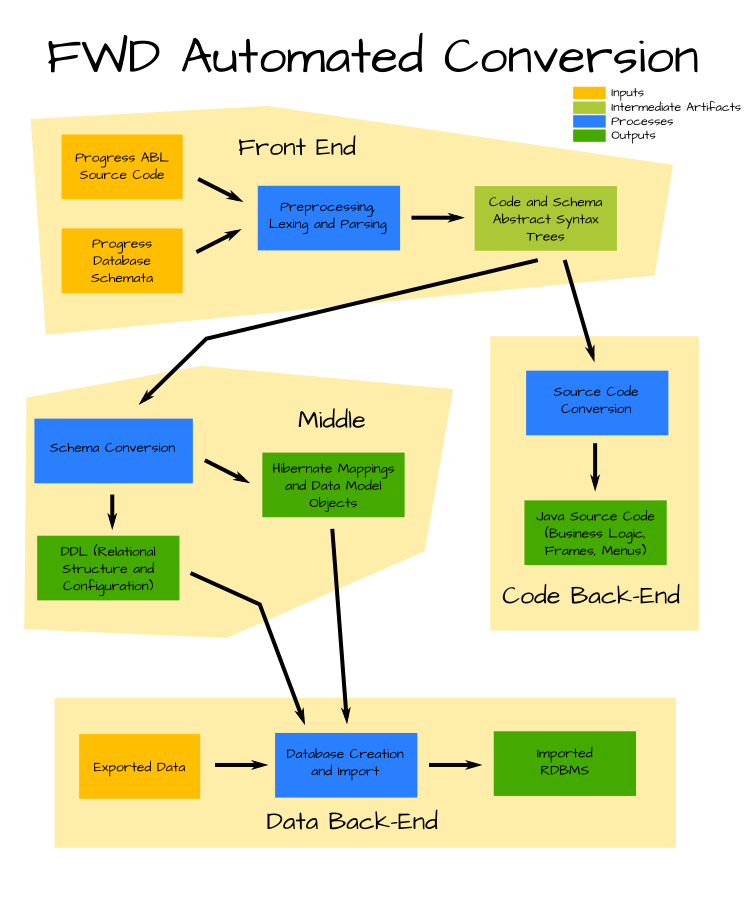
- Front End:
In this phase, we lex and parse the schemata into a schema dictionary. Then, we preprocess the application source code using an ABL-compatible preprocessor. Using the schema dictionary to resolve database references, we then lex and parse the application source code into abstract syntax trees (ASTs). ASTs provide a tree-based data representation of the source code's essential structure, which is more easily processed programmatically by downstream processes. ASTs are also created to represent the schemata for permanent tables, derived from the schemata exported from OpenEdge, as well as for temp-table definitions found in application source code.
- Middle:
The middle phase of conversion is about processing the schema ASTs created by the front end of conversion into outputs that can be used for the persistence needs of the converted application. Schema ASTs representing permanent database tables are converted to data definition language (DDL) scripts, to be used to create new relational databases in the target database environment(s). We also create data model object classes (DMOs) for both permanent tables and temp-tables statically defined in ABL source code. DMOs essentially are Java beans with getter and setter methods for each table field/column, plus annotations to represent legacy metadata. In order to use the DMOs with database tables at runtime, a set of object-to-relational mapping (ORM) documents are created at this stage as well.
- Code Back End:
The code back end uses the ASTs created by the front end conversion phase and applies thousands of rules to analyze, annotate, and transform them. At a certain point, these ASTs have been processed enough to replicate the meaning and basic structure of the original application code as a parallel set of ASTs which will represent the application as a set of Java classes. These new Java ASTs are then anti-parsed into uniformly formatted Java source code. The original code is refactored into a set of Java business logic classes and Java UI classes. The resulting code can be compiled immediately, with no post-processing or hand-editing required.
- Data Back End:
In the data back end phase, the DDL outputs of the middle phase of conversion are used to create new, empty relational databases. We use the schema ASTs created in the front end and refined in the middle phases, along with the new DMOs, to read application data exported from the application's Progress databases. That data is mapped to the new schemata and imported into the newly created relational databases.
Outputs
The primary outputs of the automated conversion process include:
- Data Definition Language SQL (DDL) to create a new database schema in a modern RDBMS;
- Java source code which can be compiled immediately and run with the FWD runtime environment;
- Object-to-Relational Mappings which enable the FWD runtime to operate with the database.
Automated Data Migration
As noted above, the middle phase of conversion generates the DDL necessary to create a new database instance in a modern relational database. Once data is exported from the associated Progress database, the outputs of the middle conversion phase can be used to import that data into the new database.
Like conversion, data import runs as an automated batch job. The time this job takes to run depends entirely upon the amount of data to be migrated and the hardware available. The import process is multi-threaded to take advantage of multiple CPUs, but it is also I/O bound, so some testing will be necessary to find the ideal throughput.
Compatible Runtime Environment
The high-level design of FWD's runtime environment is depicted in Figure 2.
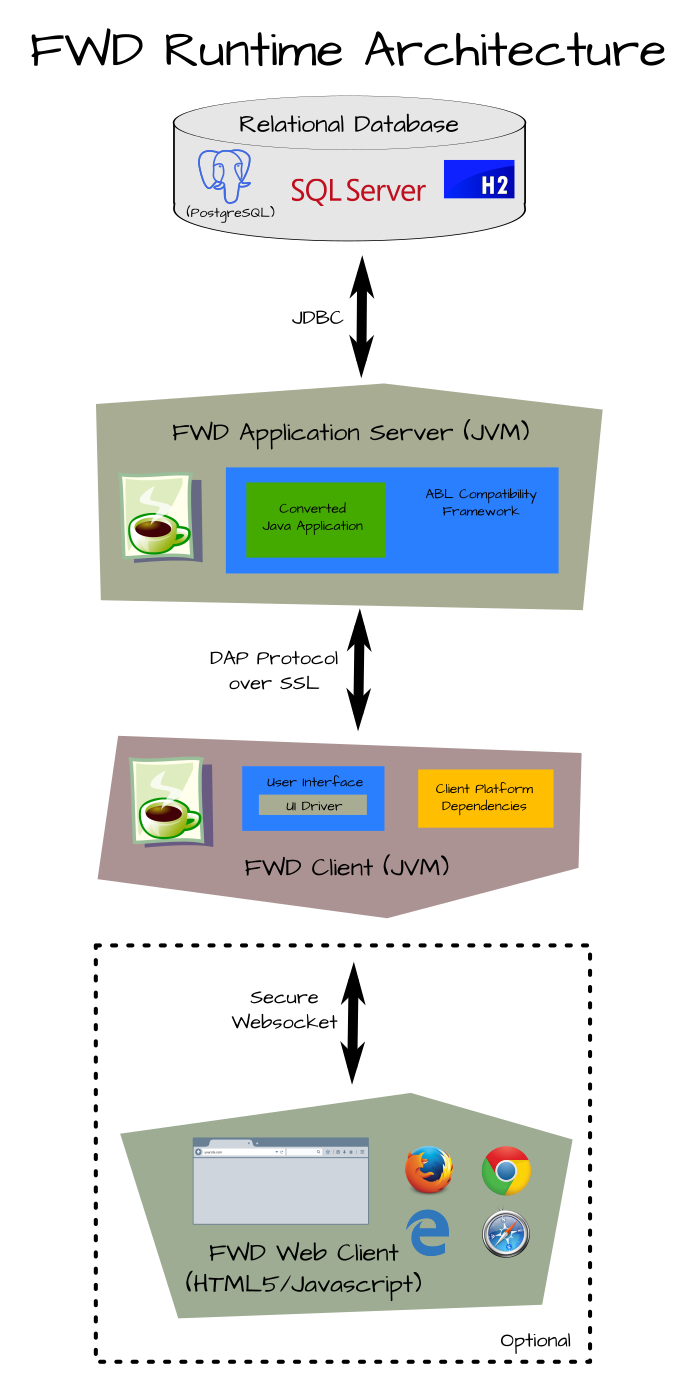
The key which enables FWD to produce a drop-in replacement for an existing Progress application is the compatible FWD runtime environment. The runtime environment consists of a custom, Java application server, plus a strict compatibility framework, which provides the legacy behavior an application expects. The runtime environment executes in a Java virtual machine (JVM), performing an equivalent service for each API call made by the converted application.
Thus, if the application operates on a GUI screen, the runtime renders that screen identically in a web browser and executes the same logic, but with Java and JavaScript. If the application opens a database transaction, populates buffers, changes records, partially undoes that unit of work, then commits, the FWD runtime does the same. However, it uses Java and a different database back end, such as PostgreSQL.
As can be seen in Figure 2, the converted application resides within the server. In the FWD runtime environment, all business logic executes on the server, even for applications with a user interface.
The FWD client is a thin presentation engine, which manages only interactions with the user and those low-level operations which must occur in the context of the client system. These include file system access, process launching, and other operating system level operations. This design allows a high degree of shared infrastructure among the various, low-level client drivers.
Learn More
If you are interested in further information regarding the FWD conversion process and runtime infrastructure, please refer to the online documentation.